
A while ago, I was given the opportunity to be involved in a data warehouse project for Zimpler, which is my current employer. I joined this project mainly because I had no experience in the field and wanted to explore how to build a data warehouse and learn the process, and I did. Here are some things I’ve learned since the beginning.
PS, some people will probably think this is basic stuff, and it probably is. Everything I’ve written about is what I’ve learned, and maybe it will help someone in the same situation as me.
If you are not familiar with the term “Data Warehouse”, it can be explained as a system that retrieves raw data from multiple sources and stores it structured in one location where it can be analyzed or used for machine learning. This can be a valuable tool for many companies. The main idea behind a data warehouse is to be able to work with large amounts of data, even in the petabyte range, quickly. Many providers, such as Snowflake or BigQuery, offer solutions for this purpose.
When discussing data warehouses, it is common to also mention data lakes. A data lake is essentially an unstructured data warehouse consisting of a collection of JSON files from various sources stored in one location.
You may wonder, “What is the difference between a database and a data warehouse?” The main difference is that a database is optimized for fast transaction handling, while a data warehouse is optimized for analytics and large data sizes. If you store terabytes of data into a Postgres database, you will notice that it slows down after a while. A data warehouse, on the other hand, is built to store a large amount of data and query it quickly.
Designing and implementing Data Warehouses requires a lot of consideration.
Let’s start with an obvious one, which you might think is “basic knowledge”: building a data warehouse is a big undertaking, even with a small amount of data. This is mainly because you need to find a good structure for your data, and in doing so, you may over-engineer the project while trying to solve issues for many people. Some people face this challenge, while others do not.
When I started the project, I was afraid that we would get stuck trying to build a data structure that suited everyone in the entire company. So, I recommend not giving too much energy to the data structure and instead focusing on building something and seeing what happens.
What I discovered by “just building something” was that we want to store the raw value from our JSON events with the same JSON structure, but within our database. This means that if we have an event that looks like:
| |
Then the SQL code for creating the table would look something like:
| |
By storing data with almost the same structure as the event, we have almost the same flexibility. In my understanding, when you run your data pipeline, you often start to aggregate data and lose flexibility. You structure your data to fit certain needs, but in doing so, you lose the ability to query your data for other purposes. Keeping your data “as raw as possible” gives you the ability to maintain flexibility. Instead of structuring your data in a way that might fit some needs, consider using SQL views. This approach enables you to solve the same problem while maintaining flexibility, although there may be a slight performance loss.
It can be difficult to know how your data should look in the end, so simply starting with the pipeline and testing things out is a good choice. That’s what I did - I tested with the data we had and created a structure. Then, I rewrote some reports to use only SQL and the data structure we were building to see how well it worked.
Source of truth.
Our source of truth is our raw events, and it will remain that way. The reason is that if we take a raw event and run it through a pipeline, the data is likely aggregated and no longer accurate. For example, a pipeline may read the raw data and remove certain identifying numbers before sending it to the data warehouse. This means that the data in the warehouse is not the truth anymore.
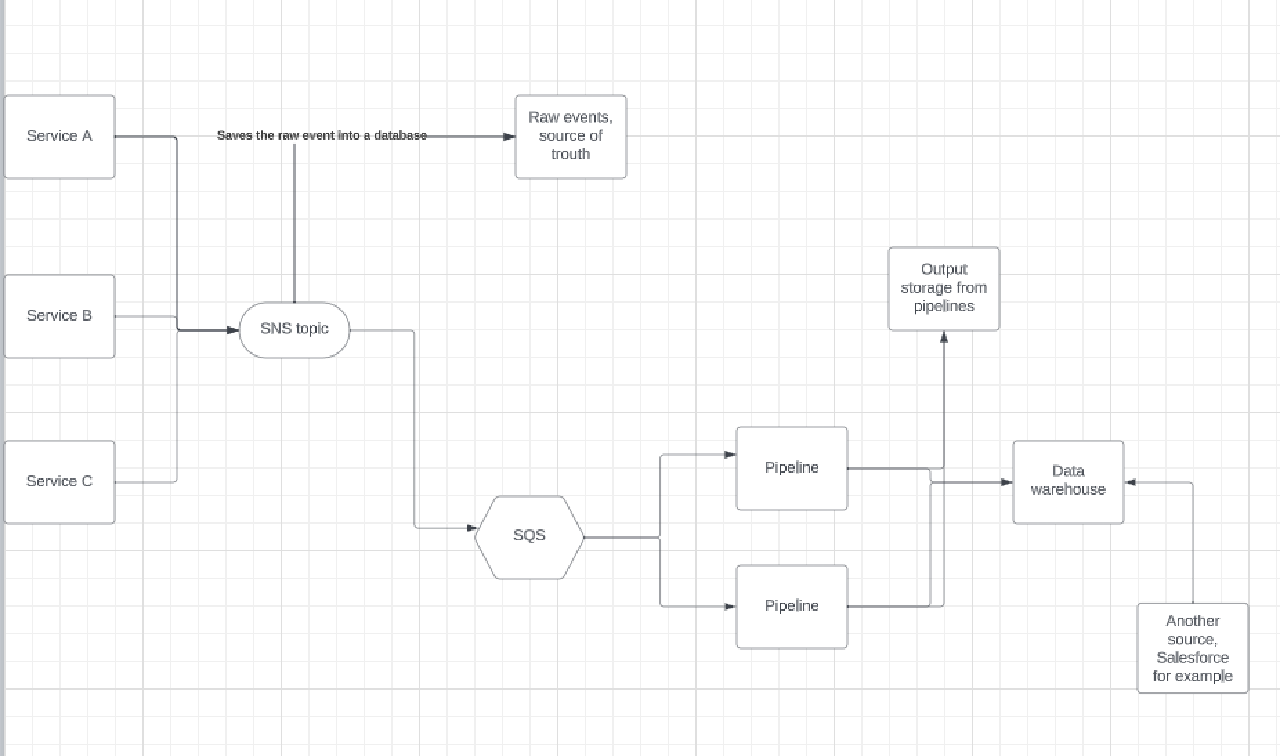
This is how our system is built. Our source of truth is “raw events” at the top, which simply stores our events. Then, we have an SQS queue listening to a topic where events are handled by pipelines. The pipeline’s output is stored in a “cold storage,” such as S3, so that we can load this data into another data warehouse if necessary. There are different ways that “cold storage” can receive its data. One way is for each pipeline to log the output and for another service to read it and then send it to S3 or another destination.
Focus on your data pipeline.
In my opinion, the data pipeline is the most significant project when building a data warehouse. It is responsible for structuring, seeding, aggregating, and cleaning up the data. The pipeline reads data from various sources in your product and consolidates it into one place. It is through the pipeline that you can control the quality of your data warehouse based on the structure it creates.
In our case, the pipeline acted as a connection between an SNS topic and a data warehouse. We connected an SQS queue to the SNS topic we used. When the pipeline received a new event, it looked at the event type and inserted the data into the corresponding table. If we did not store that event type, we acknowledged the event in the SQS queue and then discarded it.
A pipeline can also serve as an integration to a system, such as Salesforce, that loads data into your data warehouse.
Consider your data warehouse as a query system.
I recently discussed data warehouses with someone at Zimpler, and my opinion on these systems has shifted. Previously, I believed that the best approach was to send all data reactively to a data warehouse. However, I now believe that systems like Snowflake or BigQuery should only be used as query systems. The warehouse should not be the only system holding the output of the pipeline’s data.
If you send data directly from the pipeline to a warehouse without storing the output in another location (which doesn’t have to be anything special - S3 might work well), you become too dependent on the warehouse. This is not desirable because if the warehouse does not provide the desired service or if the cost is high, switching to another warehouse will be difficult.
Storing the output from the pipeline in another location (such as S3) makes it easy to switch warehouses without the risk of losing data. Instead, you can take the data from the pipeline and send it to another warehouse without having to process it again.
The end.
These are the things I wanted to write down for now. As I gain more experience, I may have more to write about. I hope this has been helpful in some way.